AWS Lambda is Amazon’s FaaS product. Pound for pound, it’s one of the best serverless computing products on the market. Easy to use, inexpensive to run (among FaaS offerings), and with compelling features like Layers, Extensions, and SnapStart, Lambda is a rock-solid choice for building serverless architectures.
However, its managed nature cuts both ways. The same FaaS features that make it so easy to use for vanilla workloads — just upload your program and go — also make it hard to use for anything that requires even a little customization, like ML models. I’ve done some significant work building out complex lambda functions for Java lately, and while deploying these complex workloads on AWS Lambda using Java is complex, the reward — a perfectly elastic, pay-for-uptime microservice architecture — is well worth the effort. But it turns out there’s a lot of the “Lambda iceberg” below the water to understand before you can expect to get these complex serverless applications working with high performance and reliability.

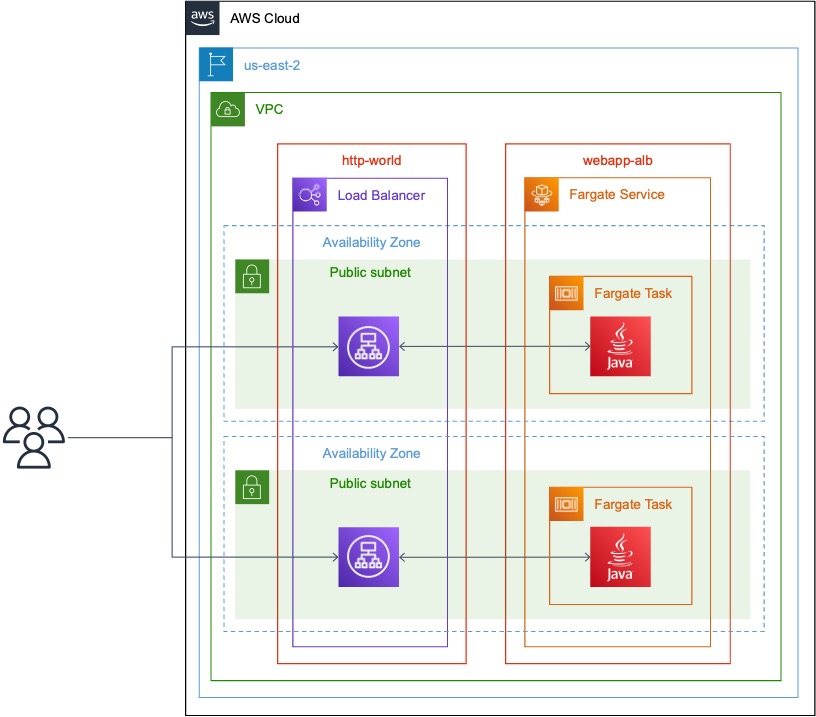
In this blog series, I will unpack what I learned in my journey to deploy an OpenCV-backed ML model onto AWS Lambda with minimal cold start, and show how the process can be used to deploy ML models on other backends, like TensorFlow Lite, onto Lambda as well.