
As part of optimizing the HumanGraphics product, I am investigating different cloud architectures and their tradeoffs. Documenting my current “default stack” for a new webapp with compute (like an API) seems like a good starting point. Here it is:
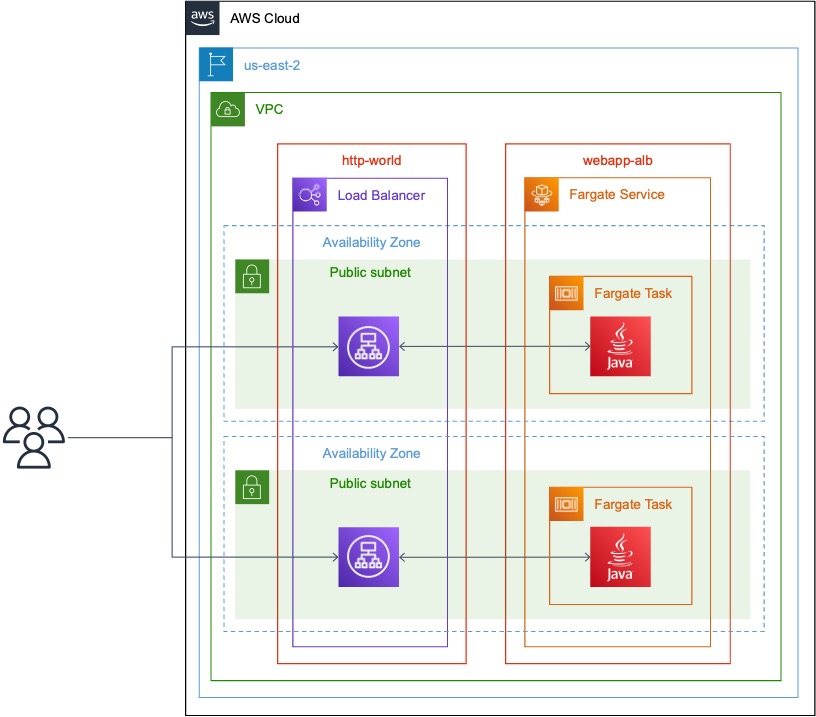
Experienced cloud engineers and architects should should look at this diagram and agree that it’s at least a sane approach to building webapps, although certainly there are others. However, a less experienced cloud user might not understand why this architecture is sane. It turns out that there’s a lot to unpack in even this simple architecture — feature differences, business pressures, tradeoffs, and more. Let’s get into it.
What is a Webapp?
This post uses “webapp” to mean any internet-facing compute-in-the-loop application, like an API or a node website. It would not include SPAs in S3, for example, since there’s no compute-in-the-loop. Of course, such a webapp may also include other components, like a DynamoDB table or RDS database, and the post includes some discussion of those components, even if they don’t appear in the diagram above.
Which Cloud Provider Should I Choose?
Obviously, there’s a lot more to write on this topic than a paragraph in a blog post! But in short, I picked AWS because
- I know it well, to the point I hold several certifications
- It works well
- It’s affordable
- The tooling is great
Certainly, there are other valid choices — GCP and Azure leap to mind — and I do use those clouds for some products (like BigQuery), but in this post, I’ll focus on AWS since it is, per the title, my default choice.
Which AWS Region Should I Choose?
First, friends don’t let friends use us-east-1. It’s tempting to use us-east-1 because it always has the highest quotas and is always in the first group of regions to get new AWS products, but it’s also the region with the most major outages, period. As a rule, I lean towards us-east-2 or us-west-1 because:
- I’m in the US, so I prefer US regions.
- Those regions also have high quotas and tend to get new releases quickly
- Those regions do not have the same history of instability
There are plenty of good reasons to pick other regions (e.g., you’re not in the US), and for some users access to the highest quotas and the newest tech is worth the stability tradeoff. But I like us-east-2 and us-west-1.
How Should I Set Up my Network?
First, you should use a VPC, since EC2-Classic networking is officially retired. So that part of the solutions is easy: you have no choice!
Given that you’re using VPCs, should you use public or private subnets?
Non-Internet Facing Applications
Any hardware that should be accessible to your application but not to the internet that also doesn’t need to access the internet (e.g., a database) should always go into a private subnet. Such hardware can be put into public subnets and made inaccessible using security groups, but such hardware placed into a private subnet is inaccessible by design and less vulnerable to configuration errors, too. Also, placing such hardware into private subnets adds only minor complexity to a deployment and adds no cost, so there’s no real drawback.
Internet-Facing Applications
Remember that public subnets reach the public internet using internet gateways and private subnets reach the public internet using NAT gateways.
Private Subnets Cost Extra for Internet-Facing Applications
If your deployment uses private subnets, then you have to use NAT Gateways to give hardware in those subnets access to the public internet. NAT Gateways are not free: for an application deployed to two AZs, the cost for NATs is $64.80/mo + $0.045/GB data processing (plus normal egress costs).
If your deployment only uses public subnets, then you only need Internet Gateways to access the public internet. Internet Gateways are free.
So private subnets cost (extra) money, and public subnets don’t. Therefore, it only makes sense to use private subnets if they add extra value for your product or organization, which would be in the form of added security.
Different Approaches to Security
Hardware in a private subnet can reach the public internet (via a NAT Gateway), but the public internet can never reach hardware in a private subnet, due to the nature of Network Address Translation (NAT). There is no way to make hardware in a private subnet (directly) accessible to the public internet. (Such hardware doesn’t even get a public IP address!) Therefore, the primary approach to security for private subnets is simply network design. As long as hardware is in a private subnet, there is an upper limit to the blast radius of configuration errors, since such hardware simply cannot be made publicly accessible.
On the other hand, hardware in a public subnet can be reached from the public internet, and relies on security groups for isolation. If the relevant security groups are properly configured, then a deployment to public subnets is just as secure as deployments to a mix of public and private subnets. (Specifically, neither deployment is more vulnerable to direct attack from the public internet.) However, there is no corresponding upper limit to the blast radius of configuration errors for hardware in public subnets, since they can (easily) be made publicly accessible, either intentionally by a bad actor or accidentally by an administrator.
Should I Use Private Subnets?
My default choice is to use public subnets only. When I deploy a new product that isn’t making money then I don’t think it makes sense to add cost. Also, if I’m the only team member working on it, then I think the risk of misconfiguration is pretty low, so I’m not concerned about blast radius. Finally, I know that switching from public subnets to a mix of public and private subnets is pretty simple and requires no downtime, so there’s no drawback to saving a little money in the short term.
Once I hand off management of the API to another team member, I move to private subnets because the added communication increases the possibility of misconfiguration, and the reduced blast radius is valuable.
However, if your application deals with highly sensitive data, like PII, then the nominal cost for NATs might be a small price to pay for incremental security, however small.
How Should I Deploy My Application?
In this day and age, all applications should be deployed using containers (e.g., docker, podman) unless there is a very good reason. (A good reason might be deploying to lambda using default runtimes, for example to take advantage of SnapStart.) Since the webapp is internet-facing, it should be load balanced across at least two AZs for high availability.
When deploying a load-balanced web application on AWS, the two cleanest options are EKS and Fargate. Both are container management infrastructure that front applications with an ALB. I find Fargate easier to use, which is why it’s my default, but EKS/Kubernetes is certainly a valid option, too.
When deploying, I create an ALB and then connect a new Fargate service to it such that new tasks are registered as targets on the ALB. New deployments are then pushed such that they cause a service re-deploy, and the application refreshes with no downtime. The Fargate service should be configured to run on two subnets in the same AZs as the load balancer with a minimum target size of at least 2. (If the target size were 1, then there would not be an instance running in two different AZs!) It can safely re-use the same subnets as the ALB for simplicity.
The ALB should perform a redirect from port 80 to port 443 so that only requests to 443 are forwarded to the application.
How Should I Configure Security Groups?
I will assume that all hardware is deployed to a public subnet, per the above discussion. (Regardless, the public and private subnet case is very similar.) The ALB and Fargate service can share one subnet per AZ.
The ALB should receive one security group (here referred to as http-world) that opens ports 80 and 443 to CIDR 0.0.0.0/0 (i.e., the world). The Fargate service should receive one security group (here referred to as webapp-alb) that opens the application port (e.g., port 8080, 3000, etc.) to the security group http-world only. (This port must match the target port from the above application deployment, or the load balancer will not be able to reach the web application.) This setup allows anyone in the world to reach the webapp’s load balancer, but only the load balancer to reach the webapp implementation.
Conclusion
Hopefully this clearly outlined my default deployment strategy for webapps on AWS and outlined some of the thinking and rationale behind the design. If there’s a desire, I can certainly post CloudFormation and/or CDK templates to deploy an example webapp using this architecture!